论文精读记录—Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
简介
RAG也就是Retrieval-Augmented Generation,即检索增强生成技术。该技术将检索与生成相结合,通过检索的方式获取知识,再通过生成的方式输出结果。该技术可以应用于各种NLP任务,如问答、文本生成等。
这个技术最初起源于2020年Facebook的一篇论文,也就是这篇Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, 2020。也是RAG相关技术的基础。

这篇论文所解决的问题非常简单,就是如何让大模型来利用外部知识来进行生成。预训练模型的知识一般是储存在参数中的,因此模型无法了解训练集之外的知识,在此前,如果要让模型拥有更多的知识,一般的做法是通过fine-tuning也就是微调来更新模型的知识。
一般来说,预训练模型能够学习大量的知识并且取得不错的效果,但它们仍然有着以下的一系列问题:
- 知识获取能力有限: 无法轻松扩展或更新知识库,每当有新的知识时,模型就需要重新进行微调,而且训练模型的成本是很高的。
- 知识操作能力有限: 难以精确地检索和利用知识。
- 缺乏可解释性: 难以解释模型决策的依据。
- 可能产生“幻觉”: 生成的文本可能包含错误信息。所有AI模型的底层原理都基于数学概率,大模型也不例外。
为了解决这些问题,这篇论文就提出了RAG的方法,将与训练的参数化记忆(seq2seq模型)与非参数化记忆(密集向量索引的维基百科)相互结合。
RAG的核心思想有两个:
- 检索相关文档: 使用预训练的神经检索器 (DPR) 从维基百科中检索与输入相关的文档。
- 结合生成: 将检索到的文档与输入一起作为上下文,使用 seq2seq 模型生成输出。
方法
这一章节详细介绍了RAG模型的构建方式与训练过程,包括模型架构、检索器和生成器组件的介绍,以及训练和编码过程。
模型
这篇文章提出了RAG模型,这个模型包括两个重要的组件,检索器和生成器。
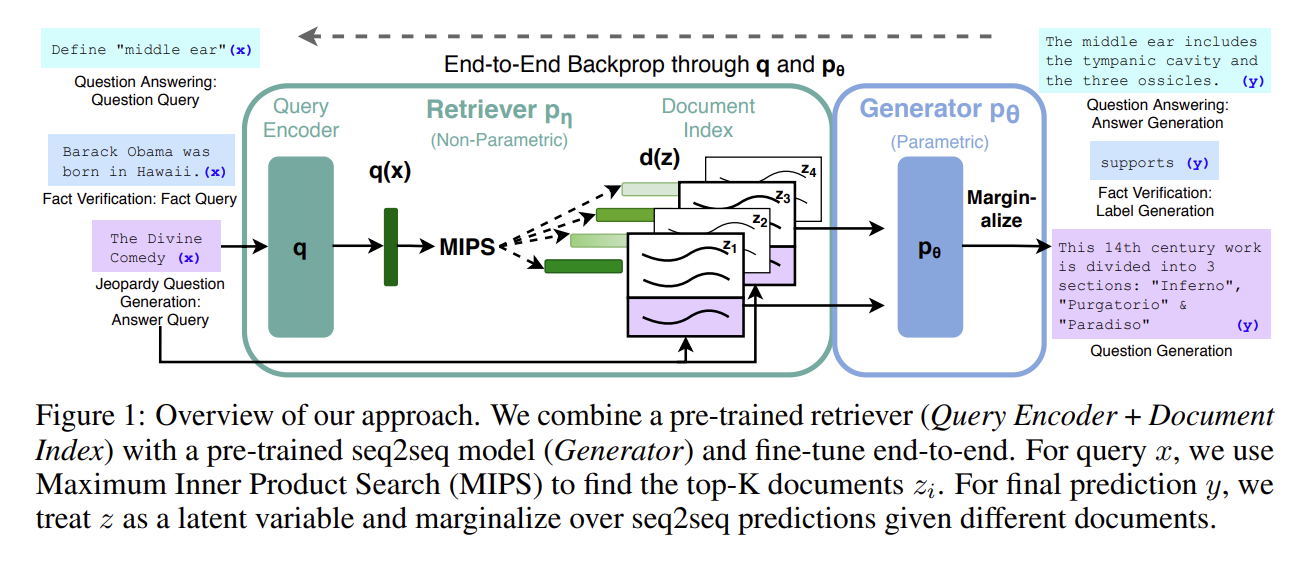
- 检索器: pη(z|x),其参数η返回给定查询x的文本段落(top-K截断)分布
- 生成器:一个由θ作为参数的生成器生成一个token基于前i-1个y,原始的输入x和一个检索的文章z
该模型使用输入序列x检索文本文档z,并在生成目标序列y时将其用作附加的上下文。
为了端到端训练检索器和生成器,这篇文章将检索到的文档视为一个潜在变量。并提出了两种RAG模型:
- RAG-Sequence模型:使用相同的检索文档来生成整个序列。模型将检索到的文档视为单个潜在变量,并通过 top-K 近似值对其进行边缘化,以获得 seq2seq 概率 p(y|x)。
- RAG-Token模型:可以针对每个目标标记检索不同的潜在文档。模型为每个文档生成下一个输出标记的分布,然后进行边缘化。
RAG-Sequence Model从技术上上来讲,就是将检索到的文档视为一个被边缘化的潜在变量,通过top-K近似来获得。具体而言,就是用检索器检索前K个文档,生成器生成每个文档的输出序列概率,然后将其边缘化。
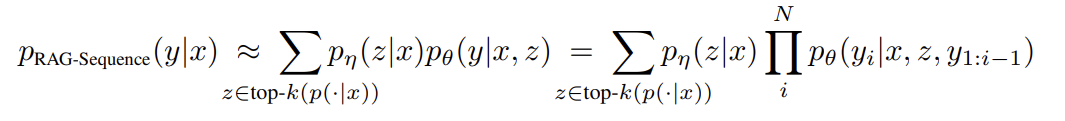
RAG-Token Model具体来及那个,就是用检索器检索前K个文档,然后生成器为每个文档生成下一个输出令牌的分布,然后将其边缘化,并使用如下令牌重复此过程。
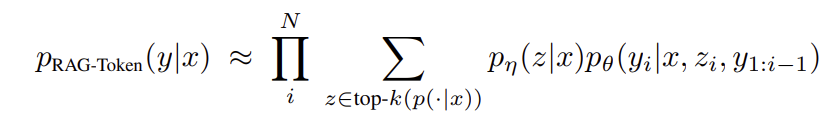
RAG还可以通过将目标类视为长度为1的目标序列来用于序列分类任务,在这种情况下,RAG-sequence和RAG-Token是等效的。
检索器:DPR
这篇论文中采用了Dense Passage Retriever(DPR)作为检索器,它是一种基于BERT的双编码架构,可以有效的找到与输入文本最相关的文档。
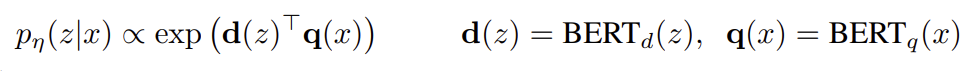
其中d(z)是由BERTBASE文档编码器生成的文档的密集表示,q(x)是由同样基于BERTBASE的查询编码器生成的查询表示。计算具有最高先验概率pη(z|x)的k个文档z的列表top-k(pη(·jx))是一个最大内积搜索(MIPS)问题,可以在次线性时间内近似求解。我们使用来自DPR的预训练双编码器来初始化我们的检索器并构建文档索引。该检索器被训练来检索包含TriviaQA问题和Natural questions答案的文档。我们把文档索引称为非参数存储器。
生成器:BERT
生成器负责根据输入文本和检索到的文档生成输出文本,比如答案。这篇论文中使用了BART作为生成器,这是一种预训练的序列到序列(seq2seq)的模型,可以生成流畅、通顺的文本。
组件pθ(yi|x;z;Y1:i−1)可以使用任何编码器-解码器建模。我们使用BART-large,一种预训练的seq2seq变压器,具有400M参数。为了在从BART生成时将输入x与检索到的内容z结合起来,我们只需将它们连接起来。BART使用去噪目标和各种不同的去噪函数进行预训练。它在多种生成任务上获得了最先进的结果,并且优于同等规模的T5模型。我们将BART发生器参数θ作为参数存储器。
训练
论文联合训练检索器和生成器组件,而不直接监督应该检索哪些文档。给定输入/输出对的微调训练语料库(xj;Yj),论文在训练期间更新文档编码器BERTd的成本很高,因为它需要定期更新文档索引,就像REALM在预训练期间所做的那样。
论文实验
论文对 RAG 模型在多个知识密集型 NLP 任务上进行了评估,包括:
- 开放域问答(Open-Domain QA):RAG 模型在三个开放域 QA 任务上超过了参数化 seq2seq 模型和任务特定检索-提取架构,取得了最先进的性能。例如,在使用 15 个检索文档的 RAG-Token 模型和使用 50 个检索文档的 RAG-Sequence 模型中,采用了贪婪解码(greedy decoding)策略。
- 语言生成任务:RAG 模型生成的语言比仅使用参数化 seq2seq 基线的语言更具体、多样且符合事实。在语言生成任务中,RAG 模型使用了 10 个检索文档,并采用了 beam search(束搜索)策略。
实验结果表明,RAG 模型在知识密集型任务上表现出显著优势,同时在语言生成质量上也优于传统模型。具体来说:
- RAG-Sequence 模型适合生成较长的连续文本,确保上下文的一致性。
- RAG-Token 模型在需要高精度知识访问的任务中表现更优,能够为每个 token 提供更相关的上下文。
| 任务类型 | 模型形式 | 检索文档数量 | 解码策略 | 性能表现 |
|---|---|---|---|---|
| 开放域问答 | RAG-Token | 15 | 贪婪解码 | 超过参数化 seq2seq 模型 |
| 开放域问答 | RAG-Sequence | 50 | 贪婪解码 | 超过任务特定检索-提取架构 |
| 语言生成 | RAG-Token/Sequence | 10 | Beam Search | 生成更具体、多样、符合事实的语言 |
总结
这篇论文是一篇开创性论文,提出了RAG模型,创新性地结合参数化与非参数化记忆,显著提升了知识密集型NLP任务的性能。
现在RAG的思想已经被广泛的应用在了对话系统、问答系统和生成式AI中,比如GPT的知识增强变体。其模块化的设计也使其易于集成到现有的NLP框架中。
RAG方法还启发了有大量的后续研究,比如改进检索算法、扩展知识库类型、优化生成质量等。其在NLP领域有着持久的影响力。
Naive RAG
以以下代码为一个简单的例子
1 | |